
빅케이스 서비스에 적용된 NLP와 언어모델
LEGALTECH
BY | 이상후
DATE | 2022. 11. 01.

자연어 처리 (NLP, Natural Language Processing)
자연어 처리는 사람들이 일상에서 사용하는 언어, 즉 자연어를 기계가 인지, 이해하고 나아가 자연어를 생성하여 사람들과 자연어를 통해 소통할 수 있도록 처리하는 기술을 주된 목적으로 하는 연구 분야입니다(이하 NLP로 약칭).

이러한 NLP 연구 성과는 이제 우리 일상에서도 쉽게 찾아볼 수 있습니다. 대표적으로, 이제 우리 일상에서 쉽게 볼 수 있는 애플 사의 시리나 구글 어시스턴트, 카카오나 라인의 음성인식 AI 스피커 등을 생각해보면, 기계가 우리가 일상적으로 사용하는 말을 이해하고 그 명령이나 요청을 처리한 후 처리 결과를 다시 자연어로 우리에게 알려주고 있습니다. 이러한 과정을 연구하는 분야가 NLP라고 할 수 있습니다.
초기의 NLP는 규칙 기반으로 연구됐습니다. 사람이 언어를 분석하여 그 안에 내재되어 있는 여러 규칙을 추출하고, 이를 처리하는 논리(알고리즘)에 따라 작업을 수행하도록 하는 코드를 작성하는 방식입니다. 이러한 방식은, 규칙을 추출하고 이를 처리하는 알고리즘을 하나하나 생성하는 수고로움은 차치하고서라도, 자연어 자체가 내재하고 있는 불규칙성에 의해 좋은 성능을 내기 매우 어렵다는 단점이 있었습니다. 사람들이 ‘일상적으로 사용하는 언어’는 학자들이 사후적으로 언어를 분석해서 만들어낸 문법 규칙을 잘 따르지 않습니다. 우리가 학교에서 국어시간에 배운 문법 규칙과 그 문법 규칙에 뒤따르는 수많은 예외들을 생각해보면 쉽게 감이 오실 것이라 생각합니다. 또, 지금도 인터넷에는 수많은 유행어가 만들어 지고 있고, 세대와 지역, 직업이나 산업 영역별로 사용하는 어휘도 다르며, 대화 또는 글이 작성된 상황과 소통하는 상대방에 따라 어투도 달라집니다.
이러한 상황에서, NLP 연구자들은 새로운 연구 방법론으로 기계가 스스로 규칙을 학습하고 정보를 추출하고 분류할 수 있는 딥러닝에 주목하기 시작했습니다. 실제로 딥러닝 방식으로 만들어진 언어 모델이 기존 방법보다 더 높은 성능을 내고 있어서, 현재 NLP 연구는 딥러닝 방식이 주류인 것으로 보입니다.
언어 모델 (LM, Language Model)
언어 모델은 연속된 단어들, 즉 문장의 확률 분포로 정의됩니다. 언어 모델을 통해 우리는 문장에 확률을 할당 할 수 있습니다. 한국어에서 띄어쓰기를 기준으로 단어를 구분한다면, ‘나는’, ‘밥을’, ‘먹었다’는 단어들이 연속될 확률이 ‘나는’, ‘법을’, ‘먹었다’는 단어들이 연속될 확률보다 더 높게 나타날 것입니다. 나아가서는, ‘나는 법을 먹었다’는 문장의 확률이 매우 낮다는 점으로부터 이 문장은 오타가 있는 문장이라는 점도 추정할 수 있습니다.
최근에는 딥러닝 방식으로 생성된 언어 모델이 확률/통계와 같은 전통적인 방법으로 생성한 언어 모델보다 높은 성능을 보이고 있습니다. 현재 AI로 분류되는 분야에서 대부분의 언어 모델이 딥러닝 방식으로 생성되고 있고, 구글 등 대기업을 중심으로 하루가 다르게 이전 언어 모델보다 더 뛰어난 성능을 보이는 언어 모델이 공개되고 있습니다.
실제 빅케이스 서비스에 쓰이는 AI 기술

빅케이스 서비스에서는 판례 데이터를 딥러닝 방식으로 학습시켜 생성한 언어 모델과 통계적 방식을 기반으로 생성한 모델 등을 복합적으로 사용하여 고도화된 판례 검색 기능을 구현했습니다.
(1) 언어 모델
일반적으로 언어 모델을 만들 때는 공개된 위키피디아, 뉴스 기사, 인터넷 게시글 등의 데이터를 이용해서 말뭉치(corpus)를 구성하고 이를 바탕으로 언어 모델을 학습시킵니다. 그러나 의료, 법률과 같은 전문 영역에서는 사용되는 어휘나 문체가 다르거나, 특정 어구를 반복적으로 사용하는 등으로 별도의 특징이 나타나는 경우가 있습니다. 지금은 많이 없어졌지만, 옛날 판례의 경우 “~한다고 하지 않을 수 없다.”와 같이 다중 부정문을 사용하는 경우를 종종 찾아볼 수 있습니다. 이와 같은 특성은 일반적인 말뭉치로 학습된 언어 모델을 이용하여 판례를 분석하는 것을 어렵게 하는 요인이 됩니다.
빅케이스는 수집한 판례 데이터와 법령 데이터를 기반으로 자체적인 언어 모델을 학습시켜 빅케이스 서비스의 여러 기능 구현에 활용하고 있습니다.
(2) AI 요약
자동 요약(Automatic summarization)은 NLP에서 널리 연구되는 분야 중 하나입니다. 주어진 글을 보다 더 짧은 문장인 요약문으로 길이를 줄이는 작업으로, 자동화된 요약 작업은 주로 2가지 접근법이 연구되고 있습니다. 하나는 주어진 글에서 핵심이 되는 문장을 선택하고 추출하는 방식(Extractive methods)과 주어진 글의 요점을 추린 요약 문장을 직접 생성하는 방식(Generative methods)입니다. 전자인 ‘추출 방식’은 글에서 핵심이 되는 문장을 선택하는 문제이므로 문법적 오류 등을 신경 쓸 필요가 없지만, 후자인 ‘생성 방식’은 컴퓨터가 다양한 입력 텍스트를 이해하고 요점을 문법적으로도 오류가 없고 조리 있게 문장을 생성해야 한다는 점에서 난이도가 높습니다.
이 때문에 실제 서비스에 적용된 자동 요약 기능은 대체로 추출 방식을 사용하는 경우가 많습니다. 최근 뉴스 서비스에서 자동 요약 기능을 찾아 볼 수 있는데, 대부분 주어진 뉴스 기사에서 핵심이 되는 문장을 선택해 보여주는 방식, 즉 추출 방식을 취하고 있습니다. 빅케이스 서비스에서도 추출 방식을 적용하여 판례의 핵심 문장을 하이라이트 처리하여 보여주는 방식으로 판례 요약 기능을 제공하고 있습니다.
네이버 뉴스의 본문 요약봇. 자동 ‘추출 기술’을 활용했다고 기재하고 있음
추출 방식의 자동 요약도 여러 가지 방법으로 구현할 수 있지만, 빅케이스는 대법원 공보에 실린 판시사항 및 판결요지를 주로 활용하여 지도 학습(Supervised learning)을 통해 판례의 핵심 문장을 찾는 모델을 학습시키고, 추가로 판시사항 및 판결요지가 없는 하급심 판결에 대해서도 학습 데이터를 생성해서 모델의 성능을 향상시켰습니다. 이 과정에서 앞서 설명 드린 언어 모델을 학습 데이터의 생성이나 문장이나 문단을 의미 단위로 구분 짓는 등의 세부적인 작업에 활용할 수 있습니다.
생성된 자동 요약 모델은 판례 데이터베이스가 추가될 때마다 판례의 핵심 문장을 찾아 자동으로 하이라이트하여 서비스하고 있고, 주기적으로 자동 요약 모델 성능을 향상시켜 새로운 모델을 만드는 작업을 하고 있습니다.

빅케이스의 Ai 요점보기 기능 예시
(3) 유사 판례
하나의 글과 다른 하나의 글을 컴퓨터를 통해 서로 비교하는 경우, 글을 수치화해서 숫자로 표현하는 방법이 있다면 컴퓨터가 글 사이의 유사도를 계산하기 쉬울 것입니다. 이와 같이 글을 다차원 벡터로 수치화하는 것을 임베딩(embedding)이라고 합니다. 이렇게 텍스트를 임베딩하고 나면, 임베딩 벡터끼리는 벡터 공간에서 얼마나 가까운지, 혹은 더하거나 빼는 등 수학적으로 계산할 수 있게 됩니다. 유명한 예시로, 단어를 임베딩한 임베딩 벡터 공간에서 왕(King) - 남자(Man) + 여자(Woman) = 여왕(Queen)이 성립한다는 예시를 들 수 있습니다.
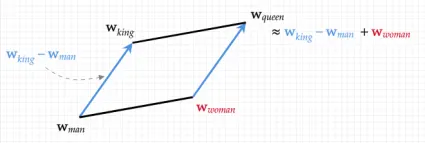
일반적으로 NLP 분야, 특히 딥러닝 방식을 사용한 임베딩은 우리가 일반적으로 생각하는 것보다 더 많은 차원을 사용하는데, 예를 들어 구글에서 2018년 공개한 언어 모델인 BERT의 경우 입력된 단어 등을 768차원의 벡터로 임베딩합니다. 이와 같이 복잡한 차원을 다루는 언어 모델을 사용하는 경우 모델의 크기가 클수록 성능이 좋아지지만, 동시에 모델의 크기와 입력 길이에 따라 필요한 연산량과 메모리 등이 기하급수적으로 증가하기 때문에 입력 길이에 제약이 생길 수 있고, 이를 해결하는 것이 NLP 연구의 과제 중 하나입니다.
빅케이스 서비스에서는 전통적인 방식과 딥러닝 방식을 비롯해 여러 가지 방식을 이용하여 판례를 임베딩하고 벡터 공간을 탐색하여 유사한 판례를 자동으로 찾아주는 모델을 구현하고 서비스에 적용했습니다. 이를 통해 사용자가 판례를 열람하면서 유사한 판례를 바로 찾아볼 수 있도록 추천하는 기능을 제공하고 있습니다.
(4) 판례 군집화 및 키워드 추출
군집화(Clustering)는 유사한 개체를 각각의 그룹으로 분류하는 것을 의미합니다. 군집화의 목적은 군집 간의 분산을 최대화하고, 군집 내 분산은 최소화하는 것이라고 말할 수 있습니다. 군집화는 크게 각 데이터가 오로지 하나의 군집에만 속하는 hard cluster와 2개 이상의 군집에 속할 수 있는 soft cluster로 나뉠 수 있습니다. hard cluster의 대표적인 모델은 k-means, hierarchical 등등이 있으며, soft cluster의 대표적 모델은 fuzzy cluster 등등이 있습니다. 이러한 카테고리화는 데이터를 다루는데 있어서 매우 중요한 부분입니다. 판례 데이터의 경우 기본적으로 형사, 민사, 행정 등의 카테고리로 분류할 수 있을 것입니다. 하지만 우리가 보다 세부적으로 판례들이 다루고 있는 사안이나 쟁점들을 기반으로 판례 데이터를 더 분류하고 싶다면, 위와 같은 군집화 방식을 적용하는 것을 고려해볼 수 있습니다. 나아가, 앞서 언급한 언어 모델을 토대로 한 문장 임베딩이나 문서 임베딩을 토대로 군집화 성능을 더 끌어올릴 수 있을 것입니다.

빅케이스에 적용된 쟁점별 판례보기 예시, 사용자가 ‘음주운전’으로만 검색한 판례를 군집화하면, 사용자에게 음주운전 중 교통사고를 낸 사례들(스크린샷 위쪽 군집), 음주운전을 이유로 징계처분을 받은 사례들(스크린샷 아래쪽 군집)을 묶어서 보여줄 수 있습니다
한편, 이와 같은 판례 군집화를 통해서 우리는 각 군집에 속한 판례들이 공통적으로 다루는 사안이나 쟁점들의 키워드도 추출 할 수 있습니다. 이러한 기술을 토픽 모델링이라고 합니다. 대표적인 모델로는 LDA가 있고, 이러한 기술들을 이용하면 주어진 문서 데이터의 키워드들을 중심으로 분류하여 각 군집의 주요 키워드들을 도출 할 수 있습니다.
맺음말
이상으로 NLP와 언어 모델에 대한 개념을 소개하고, 빅케이스에서 사용하는 AI 기술의 일부를 간략하게 소개해드렸습니다. 빅케이스에는 이 밖에도 판결 주문을 분석하여 결과를 요약하거나, 장문의 텍스트 임베딩을 활용한 서면으로 검색 등의 기능을 제공하고 있습니다. 앞으로도 계속하여 모델을 업그레이드하고 기능을 고도화하여, 사용자들에게 가장 앞선 성능의 판례 검색 서비스를 제공하고자 합니다.
Edit 신다솜 Graphic 허주경
-이 아티클은 2022년 11월 기준으로 작성되었습니다.



